
Which Type of Information You Can Extract from Instagram?
What data do you scrape from Instagram Accounts like Phone Number or Email Addresses?
- Total Number of Followers
- Instagram Bio
- Instagram Username
- Instagram Category (1 out of 1500)
- Location (10% of all users have country/city/street)
- Whether it's a company or a regular Instagram account
- Number of Posts
All the information will assist you in further monitoring your datasets. For example, if you need to search for influencers amongst your followers, you can sort your database by the number of followers. That method you quickly see in the Instagram clients are general and could be utilized to spread the word related to your brand.
How You Can Find Phone Number and Email Address From Instagram Followers?
Some users rarely know about this but, only 30-40% of the Instagram handlers have accurate information on their Instagram account.
Some of the users are adding their information wisely but, some of them not.
In the below-given points, you will come to know about how to find Email Address and mobile number on Instagram:
- Instagram Biography:
- Only 10% of all the clients purposely adding their contact information to their profile. Influencers, businesses, and daily users wish that somebody will reach out to them as they have added their email address and Phone number to their profile.
- Instagram Company Accounts:
- Only 30% of the Instagram clients are having an Instagram company account. In this kind of profile, they have extra data related to their followers like engagement %.
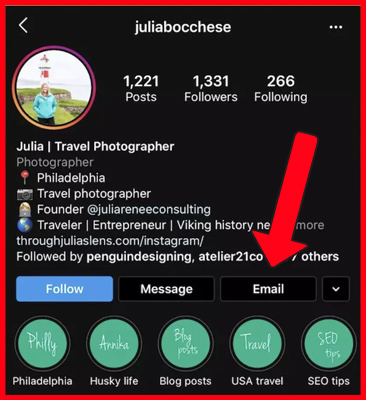
How Rapidly You Can Acquire Data from Instagram Followers?
Many data providers gather Instagram client information and can extract anyone's Instagram follower’s data rapidly.
Before letting you know how can you do this by yourself, I want to explain why sometimes it is good to easily outsource the extracting.
There are many Instagram email scraper tools available in the marketplace so that you can validate data upon extracting and they provide advanced aiming options like age, gender, location, interest.
Why You Require Additional Targeting?
Extracting Instagram supporters is targeted you may quite finish up with a bundle of users that are not related to your company.
- 90 million Instagram users are fake.
- Many users simply don’t drop in your ideal niche (location, no gender, different types of targeting, or age).
And if you are thinking of extracting emails for email marketing then the impact will be negative on your campaigns i.e. huge bounce rates.
Why Do You Need to Clean Scraped Data?
Web-Extracting means you contain a huge amount of waste in your net. Below are some examples:
- Get all emails
- Fake emails
- Spam-traps
Scraping email listings from Instagram could be utilized in two conditions - also for emailing or utilizing them as common people in Facebook Ads.
Once you generate your email operations and you will grasp out various fake emails, there's a chance that your business domain can be converted into spam. The regular emails will be measured as spam and not grasp the anticipated destination.
If you import the listing as Common Viewers, Facebook will help you in recognizing that a lot of contacts are fake which might permanently ban you.
That’s the reason why with Instagram scraper, we also confirm the emails and provides additional aims like age, gender, emails, or location-based on keywords in the client’s profile.
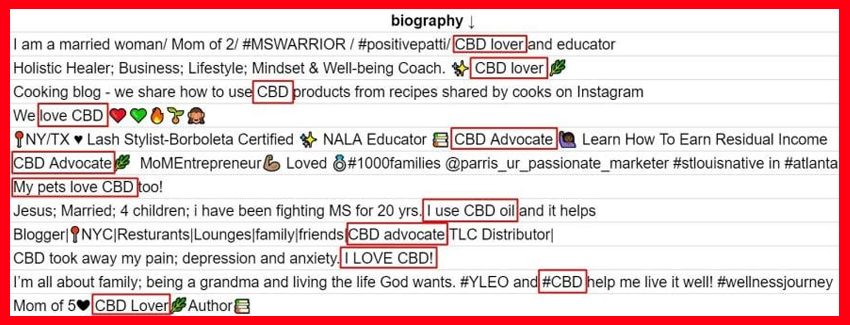
How You Can Extract Instagram Follower Data for Free?
If you are having less than 1000 supporters, you can scrape data physically. To see extra details on a profile, you are required to visit all clients with the Instagram app i.e. for a mobile user only.
Gather the information by copy-pasting it on a worksheet.
We don't suggest visiting more than 1k user-profiles physically (you can’t do that with your profile) because your account will get postponed.
Building an Instagram Follower Scraper with Python
Python is the finest way to extract anything.
Scraping data from Instagram followers using Python. Below are two simple tricks:
- 1. Extracting user IDs that track a profile, location, or hashtag (yes you can do that too)
- 2. Extracting extra information like (category, email, etc.) for all ids/usernames gathered.
Scrape Instagram Followers (Users Information) List
If you need to extract username, follower’s, you can apply the below-given code:
from datetime import datetime
from modules import compare
from modules import file_io
from modules import stats
from modules.scraper import Scraper
from modules.utils import ask_input, ask_multiple_option
groups = ['followers', 'following']
# Ask for input
target = ask_input('Enter the target username: ')
group = ask_multiple_option(options = groups + ['both']);
print('\nEnter your Instagram credentials')
username = ask_input('Username: ')
password = ask_input(is_password = True)
def scrape(group):
differs = False
scraper = Scraper(target)
startTime = datetime.now()
scraper.authenticate(username, password)
users = scraper.get_users(group, verbose=True)
scraper.close()
last_users = file_io.read_last(target, group)
if last_users:
differs = bool(compare.get_diffs(users, last_users))
if (differs or not last_users):
file_io.store(target, group, users)
# Stats
stats.numbers(len(users), scraper.expected_number)
if (differs): stats.diff(users, last_users)
print('Took ' + str(datetime.now() - startTime))
if (group == 'both'):
for group in groups:
scrape(group)
else:
scrape(group)
This is very difficult to Scrape the specific followers’ Instagram account.
Analyzing user profiles with a massive follower base will be tough to extract with this technique. For a minor account, it must do the work.
Here's all need to perform this:
- PIP
- and, Instagram credentials to log in
- Python 3
- Chrome installed
Scraping Followers Information (Category, Email)
If you only require to extract listings of an Instagram user profile, that trail a particular account, then you can do this with the initial part. If you need data of those users, then you need to extract extra information, such as mobile number, category, email addresses, of the particular profiles, etc.
This is quite difficult to do as you will require an Instagram account for login through mobile API. Here are some samples of how you can browse it.
from requests import get
from bs4 import BeautifulSoup
import sys
import re
import json
from datetime import datetime
URL = 'https://www.instagram.com'
def get_data(username):
url = '%s/%s/' % (URL, username)
page = get(url, timeout=5)
soup = BeautifulSoup(page.content, 'html.parser')
data = soup.find_all('meta', attrs={'property': 'og:description'})
photo = soup.find_all('meta', attrs={'property': 'og:image'})
text = data[0].get('content').split()
retext = re.findall(
jsontext = json.loads(retext)['entry_data']['ProfilePage'][0]
print(jsontext)
media_likes = 0
media_comments = 0
media_views = 0
media_count = 0
media_videos = 0
media_list = []
for media in jsontext['graphql']['user']['edge_owner_to_timeline_media']['edges']:
media_count += 1
media_likes += media['node']['edge_liked_by']['count']
media_comments += media['node']['edge_media_to_comment']['count']
if media['node']['is_video']:
media_videos += 1
media_views += media['node']['video_view_count']
media_list.append({
'id': '2042452950535483363',
'img_url': media['node']['thumbnail_src'],
'date_posted': datetime.fromtimestamp(media['node']['taken_at_timestamp']),
'likes': media['node']['edge_liked_by']['count']
})
else:
media_list.append({
'id': '2042452950535483363',
'img_url': media['node']['thumbnail_src'],
'date_posted': datetime.fromtimestamp(media['node']['taken_at_timestamp']),
'likes': media['node']['edge_liked_by']['count'],
})
media_video_like_engagement = 0
media_video_comment_engagement = 0
if media_videos != 0:
media_video_like_engagement = (
ig_tv_likes / ig_tv_videos) / (ig_tv_views / ig_tv_videos)
return....
For full code, you can click on the below-given link.
https://www.webscreenscraping.com/contact-us.php
If you are in trouble, then you can upload the listing of the user profile you previously get with API and develop it with an email address.
Catch Instagram Follower Information
If you are not having the capability of using Python but need to export a listing of your supporters (information) you can utilize then you can contact Web Screen Scraping. If you are aiming for less than 500 followers’ accounts, then you can export the listings without cost. The maximum number of followers you can download is about 50k.
If you want to Scrape Instagram Followers Information using Python, then you can contact Web Screen Scraping for all your queries.
Comments
Post a Comment