
We all are always eager to know the best movie or the best comedy show of all time. For all such confusions, reviews, ratings, and people all over the world utilize IMDB, an online library of such material, for trivia linked to the world of movies and television.
While people add the information, the database is owned and administered by an Amazon subsidiary. It began as a database in 1990 and was converted to the web in 1993. While anybody can examine the material on the website, if you want to make changes to the facts or add reviews, you must first register. In this blog, we'll look at how to use Python to scrape IMDB movie data from the web.
IMDB allows users to give ratings to movies and small screen shows, and these ratings have provided the basis of several lists used by movie fans and many others to establish a personal hit list. While IMDB doesn't give an API for querying its data, it does provide a textual download option. A DIY code can also be used to scrape the data.
How is Web Scraping of IMDB Data Done?
We will scrape 2 different sets of data from IMDB
- The top 250 films on IMDB
- The top 250 television series on IMDB
For each movie or show on these lists, we'll scrape particular data points. You will not want to scrape all or most of the information at once, so we've included the flexibility to adapt a parameter's value to retrieve just the top-ranked results.
Before we begin, you'll need Python 3.7 or higher, as well as the BeautifulSoup requirement and a text editor. Then you may use the python command to run the code given below. We have hardcoded the links to the two lists we mentioned earlier in the code, so no user input is required.
There are three distinct functions in the code.
get_top_rated_IMDB_hits- The execution begins here. The URL of the relevant list is sent as an argument to this function. It could be the URL for a movie list or a TV show list. We also specify the filename in which the JSON result should be saved, as well as the number of major results we desire. We retrieve certain data points from the web page itself, including the movie name and ratings, and then call the get_extra_details function to get additional data points without having to go to the movie/show specific URL.
get_web_page_content: This function gets the HTML content of the URL supplied and converts it to a BeautifulSoup object that can be processed easily. This function will return this item.
get_extra_details: This function leverages the movie or show-specific URL supplied in by all the get top-rated IMDB hits function to retrieve additional information such as the synopsis, top-star names, and director—information not available on the ranked-list homepage.
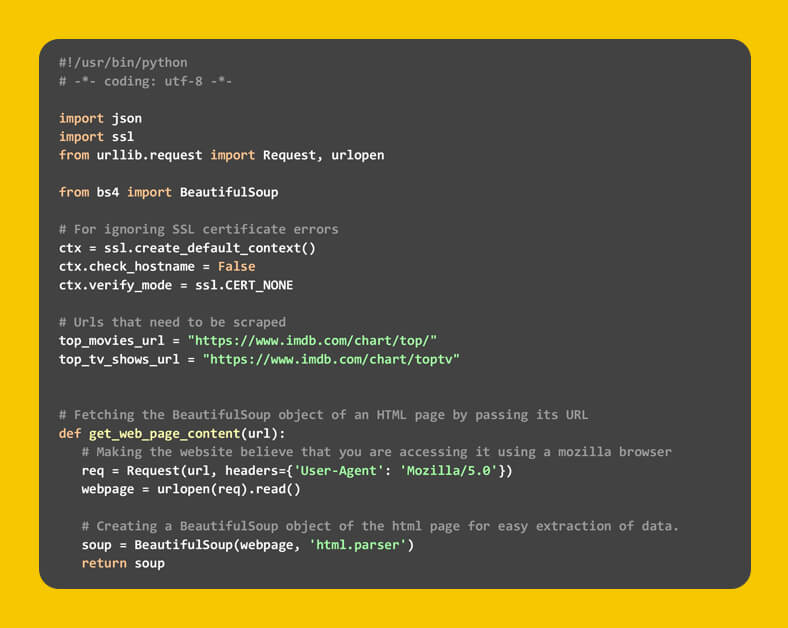

The function get top-rated IMDB hits have been called twice, once before with the movies URL and once with the TV series URL. We've also set the count to two because we only need the information for the two candidates on both lists. When you run this code, two files will appear in your directory: “movies.json” and “tv shows.json.”
The Data Points that We Scrape are:
For every movie or TV show, we scrape the other data points are:
- IMDB link for the particular show/movie
- Rank
- Name
- Year
- Ratings
- Summary
- Director name
- Writer name
- Reviews
It's worth noting that not every data point for each movie or show may be available, but whatever it will be scrapped. The JSON below displays the top two films from IMDB's top-250 film list, as retrieved by running the code above.


While we collected the data exactly as it is now and made only minor changes to the data, the data can be cleaned up even more to make the data points more usable. Here are several examples:
a) On the year, removing the brackets.
b) Separating the ratings and the number of people who submitted their ratings into two different data points.
The JSON below displays the top two television series we found on the second webpage. There are a variety of online scrapers accessible. Let's have a look at how we can scrape IMDB information for multiple TV shows from their website. The code below provides a full explanation of how to accomplish this.
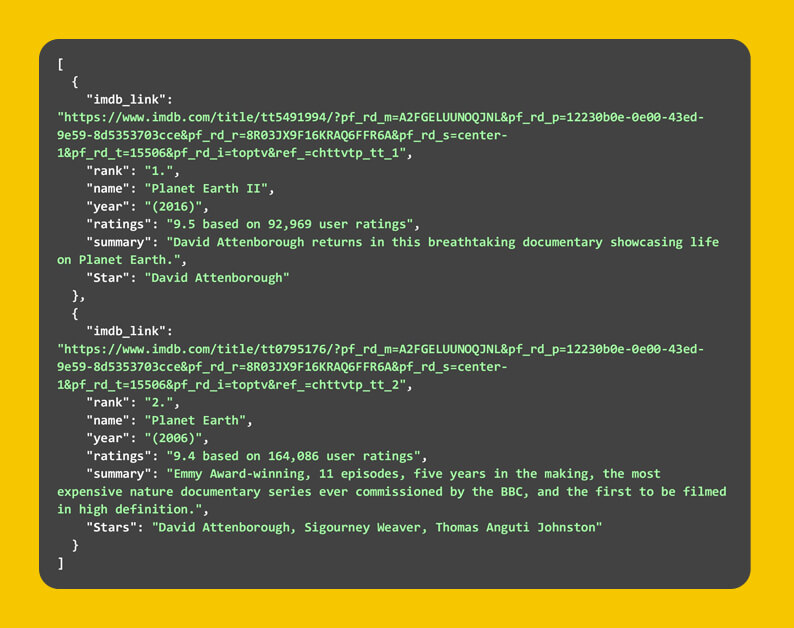
Only two items were selected from each list. You can execute the script for all 250 shows or movies, resulting in a large JSON file. You can save the extracted data in a database. However, for using the code on such a large number of connections. When web scraping IMDB data, you'll need to follow some recommended practices and keep some limits in mind.
Conclusion
If you executed this code and modified the value of “nos” to, say, 250, the code would run on all 250 movies and television series. There's a good probability that the website will detect artificial traffic from your IP address and prohibit you. You'll need to employ technologies such as IP rotation. You can optionally set a delay of a few seconds between collecting each URL's HTML information.
Even if the majority of the data you scrape was produced by volunteers, Commercial use of the data may be subject to specific restrictions. Wherever you use data scraped from various web pages, you must adhere to the rules. This is how you can use Python to scrape IMDB data from the web.
Our team at Web Screen Scraping will assist you for with hassle-free web scraping service experience where someone else takes care of the data while you focus on your core business strategy. We are proud of our DaaS solution, in which we handle everything. From scraping to retrieving the scraped data, we've got you covered.
Comments
Post a Comment