
In this blog, you will come to know about how we can scrape MercadoLibre product data using Python and BeautifulSoup.
The blog aims is to be up-to-date and you will get every particular result in real-time.
First, you need to install Python 3. If not, you can just get Python 3 and get it installed before you proceed. Then you need to install beautiful soup with pip3 install beautifulsoup4.
We will require the library’s requests, soupsieve, and lxml to collect data, break it down to XML, and use CSS selectors. Install them using.
pip3 install requests soupsieve lxml
Once installed, open an editor and type in.
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests
Now let’s go to the MercadoLibre search page and inspect the data we can get
This is how it looks.
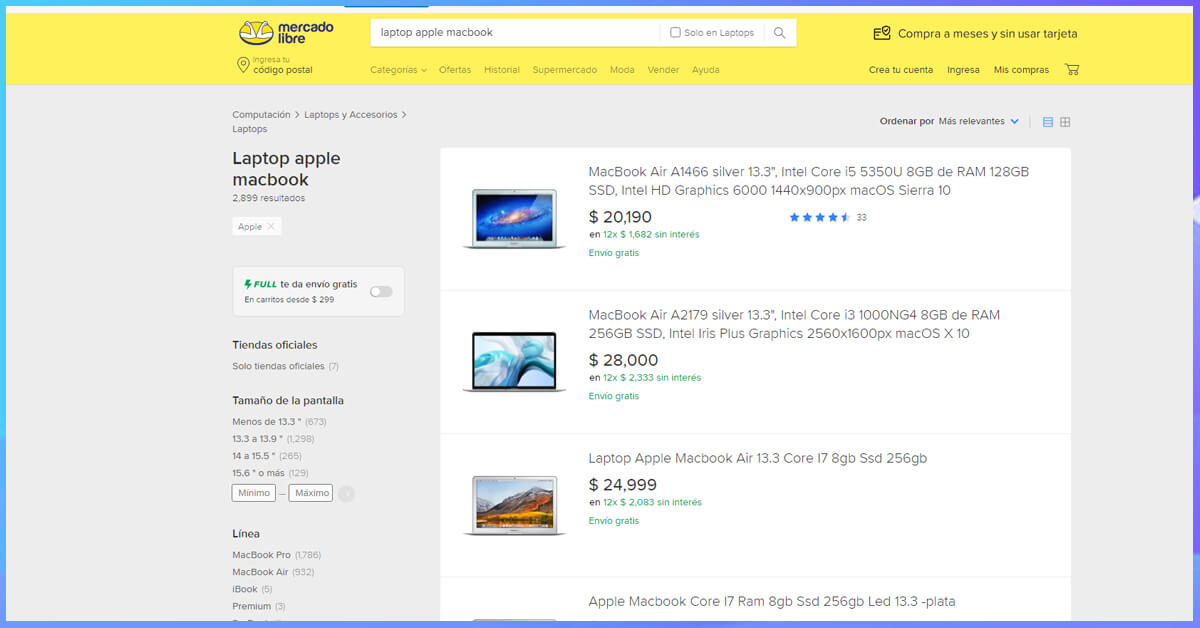
Back to our code now. Let’s try and get this data by pretending we are a browser like this.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requestsheaders = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url='https://listado.mercadolibre.com.mx/phone#D[A:phone]'
response=requests.get(url,headers=headers)
print(response)
Save this as scrapeMercado.py.
If you run it
python3 scrapeMercado.py
You will see the whole HTML page.
Now, let’s use CSS selectors to get to the data we want. To do that, let’s go back to Chrome and open the inspect tool. We now need to get to all the articles. We notice that class ‘.results-item.’ holds all the individual product details together.
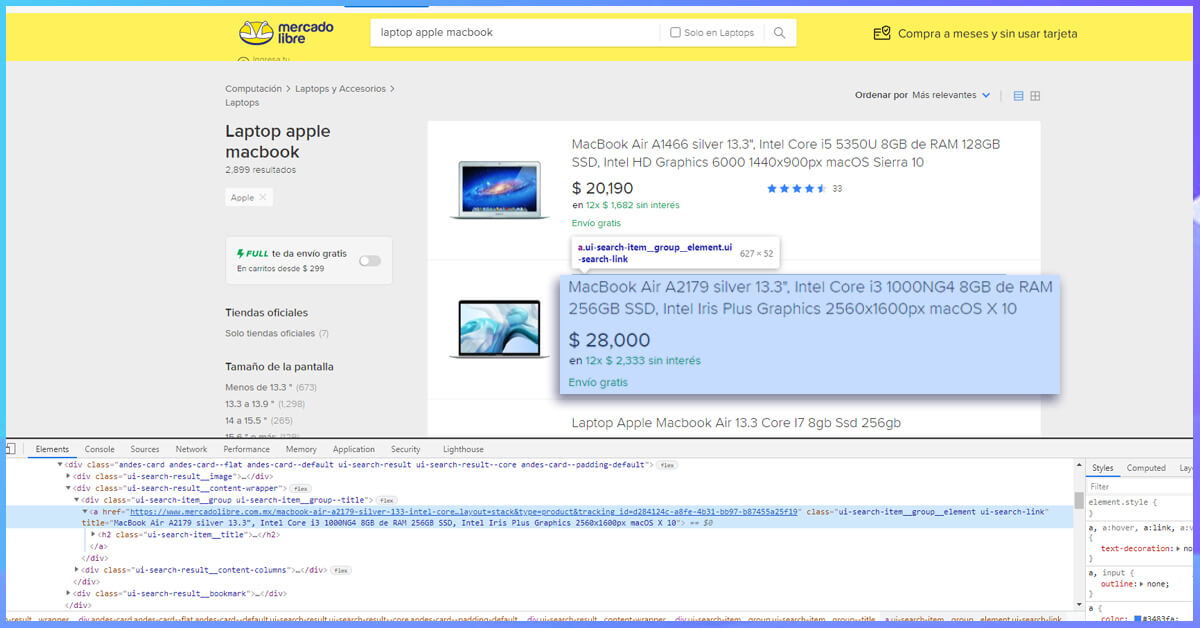
If you notice that the article title is contained in an element inside the results-item class, we can get to it like this.
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.11 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9', 'Accept-Encoding': 'identity' } #'Accept-Encoding': 'identity'url = 'https://listado.mercadolibre.com.mx/phone#D[A:phone]' response=requests.get(url,headers=headers) #print(response.content) soup=BeautifulSoup(response.content,'lxml') for item in soup.select('.results-item'): try: print('---------------------------') print(item.select('h2')[0].get_text()) except Exception as e: #raise e print('')This selects all the pb-layout-item article blocks and runs through them, looking for the element and printing its text.
So when you run it, you get the product title
Now with the same process, we get the class names of all the other data like product image, the link, and price.
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.11 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9', 'Accept-Encoding': 'identity' } #'Accept-Encoding': 'identity' url = 'https://listado.mercadolibre.com.mx/phone#D[A:phone]' response=requests.get(url,headers=headers) #print(response.content) soup=BeautifulSoup(response.content,'lxml') for item in soup.select('.results-item'): try: print('---------------------------') print(item.select('h2')[0].get_text()) print(item.select('h2 a')[0]['href']) print(item.select('.price__container .item__price')[0].get_text()) print(item.select('.image-content a img')[0]['data-src']) except Exception as e: #raise e print('')What we run, should print everything we need from each product like this.
If you need to utilize this in production and want to scale to thousands of links, then you will get that you will get IP blocked rapidly by MercadoLibre. In this scenario, using a rotating proxy service to rotate IPs is a must. You can use a service like Proxies API to route your calls through a pool of millions of residential proxies.
If you need to scale the crawling speed and don’t want to set up your infrastructure, you can utilize our Cloud-based crawler by Web Screen Scraping to easily crawl thousands of URLs at high speed from our network of crawlers.
If you are looking for the best MercadoLibre with Python and Beautiful Soup, then you can contact Web Screen Scraping for all your requirements.
Comments
Post a Comment